개인 프로젝트 리뷰: Picknic | 쉽게 찾는 맛집
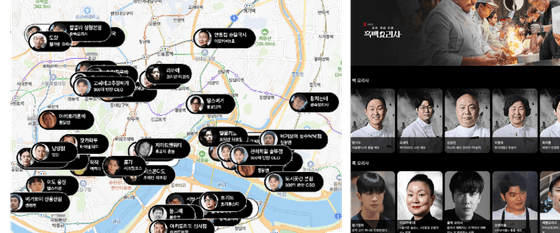
프로젝트 소개Picknic은 검증된 맛집을 지도 기반으로 쉽게 찾을 수 있는 서비스입니다.블루리본 서베이가 검증한 맛집 정보를 지역별로 편리하게 탐색할 수 있는 기능을 제공하며, 저는 사용자들이 더욱 손쉽게 지도 기반으로 주변의 맛집을 찾을 수 있도록 이 서비스를 기획했습니다.최근에는 인기 TV 프로그램인 흑백요리사 : 요리 계급 전쟁 에 등장하는 맛집 정보를 지도 기반으로 쉽게 찾아볼 수 있는 기능도 추가했습니다. 프로젝트를 시작한 이유블루리본 서베이는 검증된 맛집 정보를 제공하지만, 제가 느끼기에 모바일 사용성이 부족했습니다. 이런 훌륭한 정보를 사용자들이 더 편리하게 찾을 수 있으면 좋겠다는 생각에, 블루리본 서베이 데이터를 바탕으로 사용성을 개선한 서비스를 만들게 되었습니다.기술 스택Next.jsZustandNextUINaverMap APIStrapi서비스를 구성하면서 고민했던 부분블루리본 서베이의 맛집 정보를 사람들이 필요로 할까?처음에는 이 데이터가 사용자들에게 정말 필요할지 검증해보고 싶었습니다. 그래서 먼저 서비스를 개발하지 않고 맛집 데이터를 만들어 공유해보았습니다. 맛집 데이터를 네이버 지도에 모아서 제공하는 형태로 시작했습니다.네이버 지도에서 맛집 정보를 만들어보니 네이버 지도에는 두 가지 아쉬운 점이 있었습니다.저장 용량 한계: 네이버 지도는 리스트당 최대 1,000개의 장소만 저장할 수 있으며, 계정당 최대 5,000개의 장소만 저장 가능합니다. 서울 지역만 해도 5,000개 이상의 맛집 데이터가 있는데, 전국 데이터를 모으기에는 이 한도가 너무 적었습니다.마커의 성능: 저는 한 번에 많은 마커를 지도에 표시하고 싶었으나, 네이버 지도에서 권장하는 마커 개수는 200~300개 정도였습니다. 하지만 서울의 특정 지역만 해도 수천 개의 맛집이 존재하기 때문에 이 제한이 매우 답답했습니다. T맵은 1,000여개의 마커를 지원하지만, 역시 사용자들이 익숙한 네이버 지도를 선택하게 되었습니다.네이버 지도를 사용한 이유와 네이버 마커의 한계, 결국 Canvas지도 라이브러리는 여러개의 선택지가 있습니다. 국내 지도만 제공할 예정이기 때문에 네이버, 카카오, T맵 지도등을 사용할 수 있었습니다. 지도 라이브러리의 각기 장단점이 있습니다. 특히 T맵은 마커의 최적화가 우수하기 때문에 이 프로젝트에 사용했다면 가장 좋았을 것 같습니다. 그럼에도 네이버 지도를 사용한 이유는 사용자에게 익숙하기 때문입니다. 그럼에도 네이버 지도는 저를 좌절하게 만든 큰 단점이 있었습니다. 바로 네이버 기본 마커의 서능 한계입니다.네이버에서는 한번에 사용할 마커를 300개 이하도 권장합니다. 서울에만 5천여개의 음식점이 있고, 신사, 압구정, 논현, 강남 지역에만 천개가 넘는 음식점이 모여 있습니다. 이러한 음식점 정보를 보여주는게 핵심이라고 생각을 했습니다.네이버 지도는 동시에 렌더링되는 마커의 한계가 있기 때문에, 마커를 지우거나 클러스터링하는 방법을 제시합니다. 클러스터링은 우선 충분히 보여주고 싶은 상황에서 뭉쳐서 보여줘야 하기때문에 탐색에 불편함이 생긴다는 단점이 있었고, 현재 지도에 보이는 음식점만 보여주고 마커를 지워주기도 했습니다. 문제는 네이버의 마커는 생성할때는 성능 문제가 없지만, 지울때는 굉장한 성능 문제가 있다는 사실입니다. 그래서 초기에는 마커를 display: none으로 핸들링 했었고, 모바일에서 성능 문제를 확인하고는 도저히 이렇게 사용은 어렵다고 판단했습니다.네이버 지도에서 기본적으로 제공하는 마커를 사용하지 않고, Canvas를 통해 직접 그려보기로 했습니다. 마커의 수만큼 element로 dom에 그리는거 자체가 무겁다고 생각하고 있었고, 이러한 성능 문제가 있다면 Canvas로 해결할 수 있을거라 생각했습니다. 그러나 이 과정에서도 삽질이 있었습니다.마커를 직접 그리려면 위도/경도를 네이버 지도 안에 x,y 좌표를 가져와야 했습니다. 네이버 지도는 projection이라는 계층이 있고 현재 위도/경도에 따른 위치 정보를 가져올 수 있었습니다. 그런데 드래그를 통해 위치를 변경시키면 projection이 업데이트가 될거라 생각했는데, naverMap에서 projection를 가져와서 fromPointToCoord 함수를 사용하여 좌표를 꺼내왔는데 이 값이 업데이트가 안되어 있었습니다. 버그인지 모르겠지만, center를 변경했을때 projection에서 충분한 업데이트가 되지 않고 있었습니다. zoom이 변경될때는 업데이트가 정상적으로 되었습니다.그래도 방법은 있었습니다.// place는 음식점의 위치를 가지고 있습니다. const dpr = globalThis.devicePixelRatio || 1; // 디바이스 별로 픽셀 ratio를 가져옵니다. const projection = naverMap.getProjection(); // 투영 정보를 얻어옵니다. const originPoint = (projection as any).__targets.projection.target .containerTopLeft; // 왼쪽 상단이 기준점이 되고 이 좌표를 가져옵니다. const latlng = new naver.maps.LatLng(place.latitude, place.longitude); const offset = projection.fromCoordToOffset(latlng); // 음식점의 좌표를 offset으로 계산합니다. const x = (originPoint.x + offset.x) * dpr; // 음색점이 그려질 캔버스의 x 좌표입니다. const y = (originPoint.y + offset.y) * dpr; // 음색점이 그려질 캔버스의 y 좌표입니다. 이렇게 마커를 표현하니 모바일에서도 3000개 이상의 마커를 그려도 성능 문제가 없이 잘 그려졌습니다. 서버를 간단하게 구성하는 방법 : Strapi저는 복잡한 백엔드 구성을 원하지 않아서 Strapi를 활용해 API를 구성했습니다. Strapi는 오픈 소스 헤드리스 CMS로, 기본적인 관리 인터페이스를 제공해 손쉽게 데이터를 추가, 관리할 수 있었습니다. 특히 이 프로젝트에서는 음식점 데이터를 쉽게 관리하고 검색할 수 있는 기능이 중요했기 때문에 Strapi를 사용했습니다.로컬스토리지에 모든 음식점을 저장하기그 외에도 맛집 데이터를 브라우저에서 저장하는것에도 신경을 썼습니다. 음식점 데이터를 실시간으로 변화 하지도 않고, 지도에 표기할 음식점 정보가 모든 데이터가 있어야 보여줄 수 있어야 하므로 하루에 한번씩 로컬에 업데이트 하는 것으로 했습니다. 로컬스토리지에 음식점 정보를 저장하는데 문제점이 있었습니다. 로컬스토리지에는 음식점 정보를 문자열로 저장하려고 했는데, 5MB의 용량제한이 있습니다. 제가 처음 테스트 할 때는 몇백개의 음식점으로 했기 때문에 문제가 없었지만, 서울지역에만 5천여개의 음식점 정보가 있고, 전국을 따지면 만여개의 음식점 정보가 있습니다. 당연히 5MB를 초과했습니다. 저는 용량 문제를 해결하기 위해 처음에는 IndexedDB를 사용해볼까 했습니다. IndexedDB는 브라우저별로 조금 다르지만 사이트당 1GB를 저장할 수 있습니다. 그러나 제가 사용하는 zustand에서 상태를 브라우저에 동기화하여 저장시키는 라이브러리인 persist사용을 하는게 일반적인 방법이었고 indexedDB를 사용하는 예시를 찾지 못했습니다. 그래서 결국 로컬스토리지에 저장을 하되 문자열 데이터니까 문자열 압축을 해보자 했습니다.그래서 사용한 라이브러리가 lz-string입니다. 사용을 해보니 문자열마다 다르겠지만, 저의 경우는 반으로 압축이 되어서 약 2.9MB 정도가 되었습니다. 현재 서울 지역정보만 있기 때문에 문제가 아니지만, 전국 데이터를 모으면 용량이 커질수 있어서 이 부분은 나중에 개선을 해야할것 같습니다.장소 상세 정보를 iframe으로 해결장소의 정보는 간단히 음식점/카페 이름, 주소, 위도/경도 등의 정보만 저장하여 지도에 표기를 했습니다. 그런데 결국 내가 음식점/카페의 상세 정보를 확인할 필요가 있었습니다. 처음 생각은 음식점 정보를 크롤링해야 겠다고 생각을 했었습니다. 그런데 음식점에 관련된 정보가 종류도 많고 다뤄야 하는 정보도 너무 많았습니다. 기본정보, 운영 시간, 메뉴 정보, 리뷰 정보, 사진 등등 너무 많아서 이 데이터를 가져와서 관리하는것도 무리라고 생각했습니다.그래서 네이버의 페이지를 외부링크로 열어야겠다고 생각했습니다. 이 방법은 서비스에서 다른 서비스로 이동하면서 이탈이 될 가능성이 높은 방법이라서 단점이 매우 컸습니다. 이에 대해 뜻밖의 아이디어를 옆사람이 툭 던졌습니다. 저는 듣고 “에이.. 그게 안될텐데??” 고 생각했습니다. 바로 iframe을 통해 네이버의 음식점/카페 정보를 띄우는 거였습니다. 그런데 웬걸..? localhost에서도 아무 사이트에서도 iframe으로 네이버 페이지를 띄울수 있었던 것입니다. 그래서 지금의 방법처럼 서비스 내에서 iframe으로 자연스럽게 열도록 처리를 해습니다. 지금보면 네이버가 워낙 다른 서비스에서 연동해서 띄우기 때문에 기본적으로 허용을 하는거라고 생각은 됩니다. 흑백요리사 관련 정보 추가하기이 프로젝트의 원래 취지는 블루리본 맛집 정보를 보여주는 것이었습니다. 원래 그렇게만 만들고 끝낼 생각이었습니다. 그래서 주변 사람들에게 만든것만 공유를 했는데, 흑백요리사도 유행을 하고 라는 얘기를 해서,,, 화제성이 있는 내용이니까 내 프로젝트에도 추가해볼까 하는 생각이 들었습니다. 당시에는 흑백요리사를 보기도 전이었지만 어쨋든 요리사들의 정보와 음식점 정보를 모았습니다. 실제로 찾아보니 음식점과 출연자의 정보가 보기좋게 정리된 자료가 없었습니다. 그나마 캐치 테이블에 요리사 정보까지 있긴 했으나 탐색하기 조금 불편하게 느꼈습니다. 그리고 다행히 네이버 지도에서는 흑백요리사 출연진 음식점 리스튼 만들어서 공식적으로 공유했고 저는 이 정보를 사용할 수 있었습니다. 소감이 프로젝트에서 가장 시간을 많이 썼던 부분은 개발이 아닌 데이터를 모으는 일이었습니다. 모든 음식점 정보를 실제 위치를 찾고 직접 네이버 플레이스에서 확인하고 데이터를 쌓는 과정이 정말 오래걸렸습니다. 또 흑백 요리사의 요리사 정보도 꽁꽁 숨겨져 있어서 찾는데 많은 시간이 걸렸습니다.정말 시간을 많이 들여서 공들여 프로젝트를 진행했습니다. 결과물이 무엇보다 괜찮은것 같아서 굉장히 뿌듯합니다. 정말 재밌게 개발했고, 쓸모있는 프로젝트를 만든것 같아서 기분이 매우 좋습니다. 만들면서 아이디어가 계속 떠올라서 프로젝트를 계속해서 개선하는 과정을 정말 재밌게 즐겼습니다. 특히 마커를 정말 많이 고민 했는데, 결과물이 좋아서 너무 만족스러웠습니다.